
Our NEH-funded Neatline project has inspired the Scholars’ Lab to develop or enhance several new Omeka plugins recently. (See our full list.)
One of these is FedoraConnector, which is designed to enable administrators to attach Fedora datastreams (a digital object – whether image, XML like TEI or EAD, or video) to Omeka items. This is fundamentally different from attaching files to an item–the datastream is not duplicated and stored within Omeka’s archive. Rather, a reference to the Fedora object (PID) is stored within a new table in the Omeka database that associates the item with the URL of the datastream that is accessed (and rendered) with Fedora’s REST API. The plugin also supports importing Dublin Core and MODS metadata into the DC Element Set in Omeka. The importers can be extended to map from any metadata standard into DC.
The benefit to this architecture is that it enables dynamic rendering of the most current version of the Fedora object, and thus there is no issue about storing duplicate files in the Omeka disk space that can be deprecated by updates to the original Fedora object. Additionally, FedoraConnector can take advantage of institutional-specific services that are developed for delivering content. For example, thumbnail and medium-sized page images are rendered in real time by querying the University of Virginia Library’s JPEG2000 server and requesting deliverables at a specific dimension. Disseminators, or handler functions for rendering Fedora content based on mime-type and/or datastream type, are extensible.

TEI document from Fedora
Earlier this year, we released a beta version of a plugin for rendering TEI files into HTML within Omeka. Called TeiDisplay, this plugin was enhanced by the insertion of several hooks that execute FedoraConnector functions (if FedoraConnector is installed) to render TEI XML datastreams on the fly directly from the repository. TeiDisplay supports, as the documentation for the plugin indicates, selection of customized XSLT stylesheets and two display types: entire document and segmental view (with table of contents and by-section rendering). Indeed, documents coming from Fedora can be rendered dynamically with the same set of options.
But what about indexing the document? This is why the Scholars’ Lab developed SolrSearch last summer to replace Omeka’s default mySQL search with the more advanced search options afforded by Solr, an open source search index. SolrSearch supports facets, sorting, hit highlighting, and a handful of other options. Originally designed to index the full text of Omeka files with a text/xml mime-type, SolrSearch was enhanced to index the full text of Fedora datastreams with a text/xml mime-type as well, enabling full text searching, faceted browsing, and hit highlighting of the aforementioned TEI files referenced from a repository.
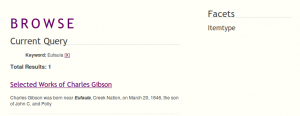
Solr search of TEI file in Omeka
So in essense, the range of plugins the Scholars’ Lab has created for Omeka can enable creation of attractive and cutting-edge public user interfaces for collections of Fedora objects. Coupled with our Neatline plugins, which are all about geospatial and temporal interpretation of archival collections, this work bridges a well-recognized gap between the volume of digital content housed in sophisticated repositories and the curators, scholars, and end users who seek access to it and wish to interpret it in online exhibits.